如何避免这8个常见的深度学习/计算机视觉错误?
磐创AI人是不完美的,我们经常在程序中犯错误。有时这些错误很容易发现:你的代码根本不能工作,你的应用程序崩溃等等。但是有些bug是隐藏的,这使得它们更加危险。
在解决深度学习问题时,由于一些不确定性,很容易出现这种类型的bug:很容易看到web应用端点路由请求是否正确,而不容易检查你的梯度下降步骤是否正确。然而,在DL从业者生涯中有很多错误是可以避免的。
我想分享一些我的经验,关于我在过去两年的计算机视觉工作中看到或制造的错误。我在会议上谈到过这个话题,很多人在会后告诉我:“是的,伙计,我也有很多这样的错误。”我希望我的文章可以帮助你至少避免其中的一些问题。
1.翻转图像和关键点
假设一个关键点检测问题的工作。它们的数据看起来像图像和一系列关键点元组,例如[(0,1),(2,2)],其中每个关键点是一对x和y坐标。
让我们对这个数据实现一个基本的数据增强:
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):
img = np.fliplr(img)
h, w, *_ = img.shape
kpts = [(y, w - x) for y, x in kpts]
return img, kpts
看起来好像是正确的,嗯,让我们把结果可视化一下:
mage = np.ones((10, 10), dtype=np.float32)
kpts = [(0, 1), (2, 2)]
image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)
img1 = image.copy()
for y, x in kpts:
img1[y, x] = 0
img2 = image_flipped.copy()
for y, x in kpts_flipped:
img2[y, x] = 0
_ = plt.imshow(np.hstack((img1, img2)))
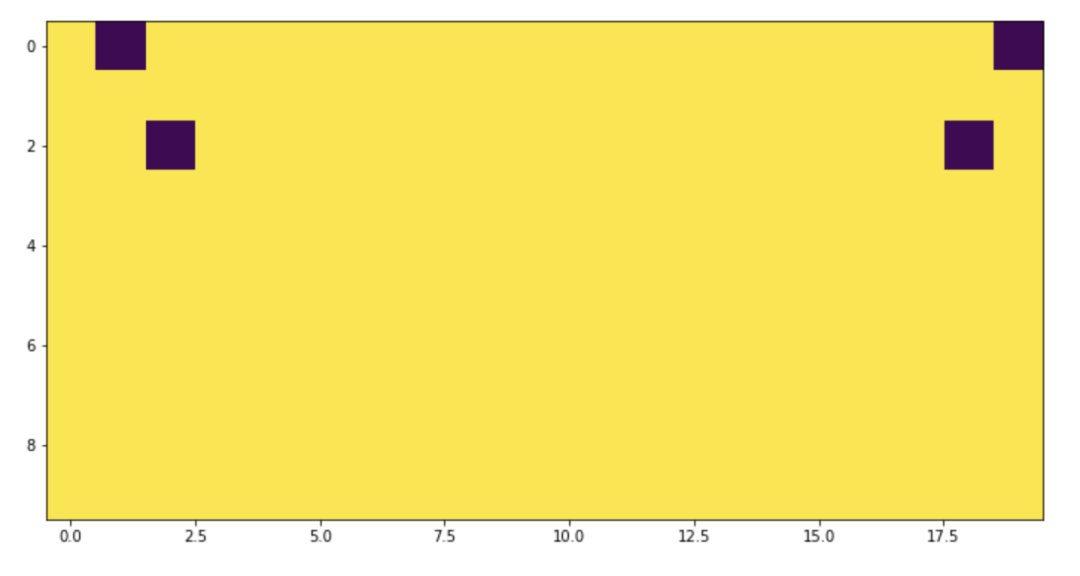
不对称看起来很奇怪!如果我们检查极值的情况呢?
image = np.ones((10, 10), dtype=np.float32)
kpts = [(0, 0), (1, 1)]
image_flipped, kpts_flipped = flip_img_and_keypoints(image, kpts)
img1 = image.copy()
for y, x in kpts:
img1[y, x] = 0
img2 = image_flipped.copy()
for y, x in kpts_flipped:
img2[y, x] = 0
out:
IndexError
Traceback (most recent call last)
<ipython-input-5-997162463eae> in <module>
8 img2 = image_flipped.copy()
9 for y, x in kpts_flipped:
---> 10 img2[y, x] = 0
IndexError: index 10 is out of bounds for axis 1 with size 10
程序报错了!这是一个典型的差一误差。正确的代码是这样的:
def flip_img_and_keypoints(img: np.ndarray, kpts: Sequence[Sequence[int]]):
img = np.fliplr(img)
h, w, *_ = img.shape
kpts = [(y, w - x - 1) for y, x in kpts]
return img, kpts
我们可以通过可视化来检测这个问题,而在x = 0点的单元测试也会有帮助。
2.还是关键点问题
即使在上述错误被修复之后,仍然存在问题。现在更多的是语义上的问题,而不仅仅是代码上的问题。
假设需要增强具有两只手掌的图像。看起来好像没问题-左右翻转后手还是手。
但是等等!我们对我们拥有的关键点语义一无所知。如果这个关键点的意思是这样的:
kpts = [
(20, 20), # 左小指
(20, 200), # 右小指
...
]
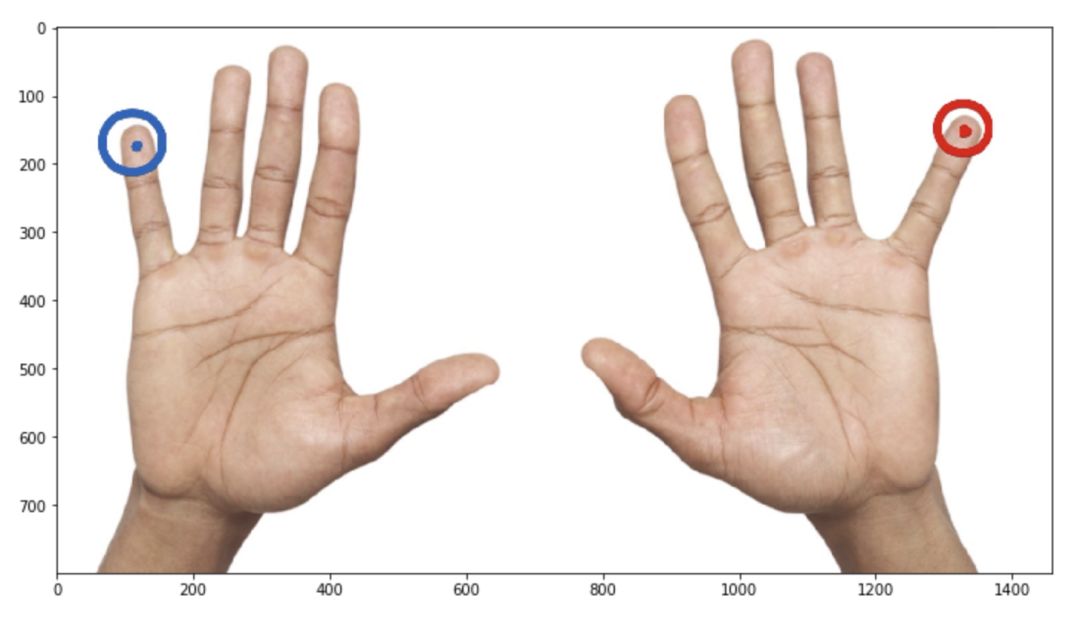
这意味着增强实际上改变了语义:左变成右,右变成左,但我们不交换数组中的关键点索引。它会给训练带来大量的噪音和更糟糕的度量。
我们应该吸取教训:
在应用增强或其他特性之前,要了解和考虑数据结构和语义;
保持你的实验原子性:添加一个小的变化(例如一个新的变换),如果分数已经提高,检查它如何进行和合并。
3.编码自定义损失函数
熟悉语义分割问题的人可能知道IoU度量。不幸的是,我们不能直接用SGD来优化它,所以常用的方法是用可微损失函数来近似它。让我们编码实现一个!
def iou_continuous_loss(y_pred, y_true):
eps = 1e-6
def _sum(x):
return x.sum(-1).sum(-1)
numerator = (_sum(y_true * y_pred) + eps)
denominator = (_sum(y_true ** 2) + _sum(y_pred ** 2)
- _sum(y_true * y_pred) + eps)
return (numerator / denominator).mean()
看起来不错,让我们测试一下:
In [3]: ones = np.ones((1, 3, 10, 10))
...: x1 = iou_continuous_loss(ones * 0.01, ones)
...: x2 = iou_continuous_loss(ones * 0.99, ones)
In [4]: x1, x2
Out[4]: (0.010099999897990103, 0.9998990001020204)
在x1中,我们计算了与正确数据完全不同的数据的损失,而x2则是非常接近正确数据的数据损失结果。我们期望x1很大因为预测很糟糕,x2应该接近0。但是结果与我期望的有差别,哪里出现错误了呢?
上面的函数是度量的一个很好的近似。度量不是一种损失:它通常(包括这种情况)越高越好。当我们使用SGD最小化损失时,我们应该做一些改变:
def iou_continuous(y_pred, y_true):
eps = 1e-6
def _sum(x):
return x.sum(-1).sum(-1)
numerator = (_sum(y_true * y_pred) + eps)
denominator = (_sum(y_true ** 2) + _sum(y_pred ** 2)
- _sum(y_true * y_pred) + eps)
return (numerator / denominator).mean()
def iou_continuous_loss(y_pred, y_true):
return 1 - iou_continuous(y_pred, y_true)
这些问题可以从两个方面来确定:
编写一个单元测试来检查损失的方向
运行健全性检查
4.当我们遇到Pytorch的时候
假设有一个预先训练好的模型。编写基于ceevee API的Predictor 类。
from ceevee.base import AbstractPredictor
class MySuperPredictor(AbstractPredictor):
def __init__(self,
weights_path: str,
):
super().__init__()
self.model = self._load_model(weights_path=weights_path)
def process(self, x, *kw):
with torch.no_grad():
res = self.model(x)
return res
@staticmethod
def _load_model(weights_path):
model = ModelClass()
weights = torch.load(weights_path, map_location='cpu')
model.load_state_dict(weights)
return model
这个代码正确吗?也许!对于某些模型来说确实是正确的。例如,当模型没有dropout或norm 层,如torch.nn.BatchNorm2d。
但是对于大多数计算机视觉应用来说,代码忽略了一些重要的东西:转换到评估模式。
如果试图将动态PyTorch图转换为静态PyTorch图,这个问题很容易意识到。torch.jit模块用于这种转换。
In [3]: model = nn.Sequential(
...: nn.Linear(10, 10),
...: nn.Dropout(.5)
...: )
...:
...: traced_model = torch.jit.trace(model, torch.rand(10))
/Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/jit/__init__.py:914: TracerWarning: Trace had nondeterministic nodes. Did you forget call .eval() on your model? Nodes:
%12 : Float(10) = aten::dropout(%input, %10, %11), scope: Sequential/Dropout[1] # /Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/nn/functional.py:806:0
This may cause errors in trace checking. To disable trace checking, pass check_trace=False to torch.jit.trace()
check_tolerance, _force_outplace, True, _module_class)
/Users/Arseny/.pyenv/versions/3.6.6/lib/python3.6/site-packages/torch/jit/__init__.py:914: TracerWarning: Output nr 1. of the traced function does not match the corresponding output of the Python function. Detailed error:
Not within tolerance rtol=1e-05 atol=1e-05 at input[5] (0.0 vs. 0.5454154014587402) and 5 other locations (60.00%)
check_tolerance, _force_outplace, True, _module_class)
一个简单的解决办法:
In [4]: model = nn.Sequential(
...: nn.Linear(10, 10),
...: nn.Dropout(.5)
...: )
...:
...: traced_model = torch.jit.trace(model.eval(), torch.rand(10))
# 没有警告!
torch.jit.trace运行模型几次并比较结果。
然而torch.jit.trace并不是万能的,你应该了解并记住。
5.复制粘贴问题
很多东西都是成对存在的:训练和验证、宽度和高度、纬度和经度……如果你仔细阅读,你会很容易发现一个bug是由某一个成员中复制粘贴到另外一个成员中引起的:
def make_dataloaders(train_cfg, val_cfg, batch_size):
train = Dataset.from_config(train_cfg)
val = Dataset.from_config(val_cfg)
shared_params = {'batch_size': batch_size, 'shuffle': True, 'num_workers': cpu_count()}
train = DataLoader(train, **shared_params)
val = DataLoader(train, **shared_params)
return train, val
不仅仅是我犯了愚蠢的错误,例如。流行的albumentations库中也有类似的问题。
# https://github.com/albu/albumentations/blob/0.3.0/albumentations/augmentations/transforms.py
def apply_to_keypoint(self, keypoint, crop_height=0, crop_width=0, h_start=0, w_start=0, rows=0, cols=0, **params):
keypoint = F.keypoint_random_crop(keypoint, crop_height, crop_width, h_start, w_start, rows, cols)
scale_x = self.width / crop_height
scale_y = self.height / crop_height
keypoint = F.keypoint_scale(keypoint, scale_x, scale_y)
return keypoint
不过别担心,现在已经修复好了。
如何避免?尽量以不需要复制和粘贴的方式编写代码。
下面这种编程方式不是一个好的方式:
datasets = []
data_a = get_dataset(MyDataset(config['dataset_a']), config['shared_param'], param_a)
datasets.append(data_a)
data_b = get_dataset(MyDataset(config['dataset_b']), config['shared_param'], param_b)
datasets.append(data_b)
而下面的方式看起来好多了:
datasets = []
for name, param in zip(('dataset_a', 'dataset_b'),
(param_a, param_b),
):
datasets.append(get_dataset(MyDataset(config[name]), config['shared_param'], param))
6.正确的数据类型让我们编写一个新的增强:def add_noise(img: np.ndarray) -> np.ndarray:
mask = np.random.rand(*img.shape) + .5
img = img.astype('float32') * mask
return img.astype('uint8')
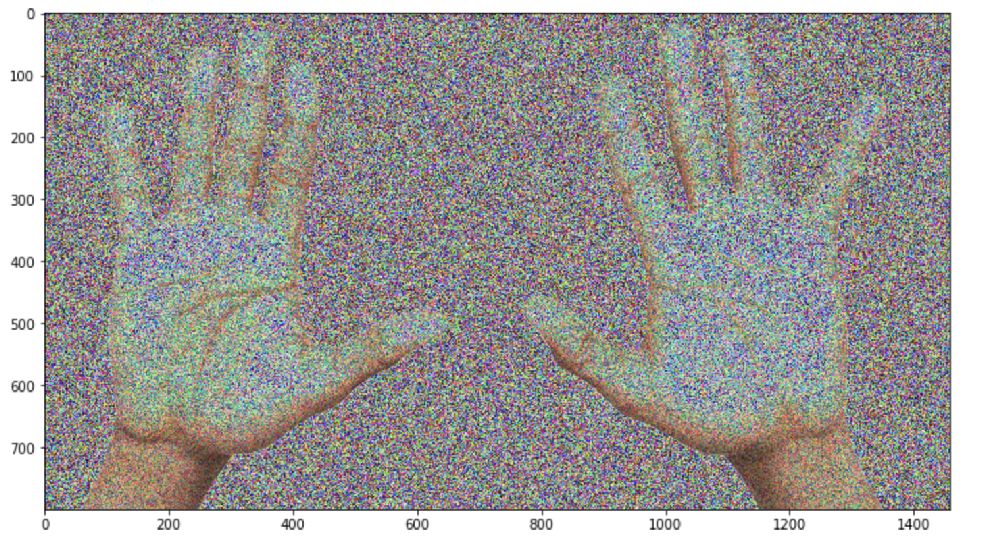
图像已被更改。这是我们所期望的吗?嗯,可能修改得有点过了。
这里有一个危险的操作:将float32转换为uint8。它可能会导致溢出:
def add_noise(img: np.ndarray) -> np.ndarray:
mask = np.random.rand(*img.shape) + .5
img = img.astype('float32') * mask
return np.clip(img, 0, 255).astype('uint8')
img = add_noise(cv2.imread('two_hands.jpg')[:, :, ::-1])
_ = plt.imshow(img)
看起来好多了,是吧?
顺便说一句,还有一种方法可以避免这个问题:不要重造轮子,不要从头开始编写增强代码,而是使用现有的增强,比如:albumentations.augmentations.transforms.GaussNoise。
我曾经犯过另一个同样的错误。
raw_mask = cv2.imread('mask_small.png')
mask = raw_mask.astype('float32') / 255
mask = cv2.resize(mask, (64, 64), interpolation=cv2.INTER_LINEAR)
mask = cv2.resize(mask, (128, 128), interpolation=cv2.INTER_CUBIC)
mask = (mask * 255).astype('uint8')
_ = plt.imshow(np.hstack((raw_mask, mask)))
这里出了什么问题?首先,用三次样条插值调整mask的大小是一个坏主意。与转换float32到uint8的问题是一样的:三次样条插值的输出值会大于输入值,会导致溢出。

我在做可视化的时候发现了这个问题。在你的训练循环中到处使用断言也是一个好主意。
7. 拼写错误发生
假设需要对全卷积网络(如语义分割问题)和一个巨大的图像进行推理。该图像是如此巨大,没有机会把它放在你的GPU上 -例如,它可以是一个医疗或卫星图像。
在这种情况下,可以将图像分割成网格,独立地对每一块进行推理,最后合并。此外,一些预测交叉可能有助于平滑边缘的伪影
让我们编码实现吧!
from tqdm import tqdm
class GridPredictor:
"""
你有GPU内存限制时,此类可用于预测大图像的分割掩码
"""
def __init__(self, predictor: AbstractPredictor, size: int, stride: Optional[int] = None):
self.predictor = predictor
self.size = size
self.stride = stride if stride is not None else size // 2
def __call__(self, x: np.ndarray):
h, w, _ = x.shape
mask = np.zeros((h, w, 1), dtype='float32')
weights = mask.copy()
for i in tqdm(range(0, h - 1, self.stride)):
for j in range(0, w - 1, self.stride):
a, b, c, d = i, min(h, i + self.size), j, min(w, j + self.size)
patch = x[a:b, c:d, :]
mask[a:b, c:d, :] += np.expand_dims(self.predictor(patch), -1)
weights[a:b, c:d, :] = 1
return mask / weights
有一个符号输入错误,可以很容易地找到它,检查代码是否正确:
class Model(nn.Module):
def forward(self, x):
return x.mean(axis=-1)
model = Model()
grid_predictor = GridPredictor(model, size=128, stride=64)
simple_pred = np.expand_dims(model(img), -1)
grid_pred = grid_predictor(img)
np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)
AssertionError Traceback (most recent call last)
<ipython-input-24-a72034c717e9> in <module>
9 grid_pred = grid_predictor(img)
10
---> 11 np.testing.assert_allclose(simple_pred, grid_pred, atol=.001)
~/.pyenv/versions/3.6.6/lib/python3.6/site-packages/numpy/testing/_private/utils.py in assert_allclose(actual, desired, rtol, atol, equal_nan, err_msg, verbose)
1513 header = 'Not equal to tolerance rtol=%g, atol=%g' % (rtol, atol)
1514 assert_array_compare(compare, actual, desired, err_msg=str(err_msg),
-> 1515 verbose=verbose, header=header, equal_nan=equal_nan)
1516
1517
~/.pyenv/versions/3.6.6/lib/python3.6/site-packages/numpy/testing/_private/utils.py in assert_array_compare(comparison, x, y, err_msg, verbose, header, precision, equal_nan, equal_inf)
839 verbose=verbose, header=header,
840 names=('x', 'y'), precision=precision)
--> 841 raise AssertionError(msg)
842 except ValueError:
843 import traceback
AssertionError:
Not equal to tolerance rtol=1e-07, atol=0.001
Mismatch: 99.6%
Max absolute difference: 765.
Max relative difference: 0.75000001
x: array([[[215.333333],
[192.666667],
[250. ],...
y: array([[[ 215.33333],
[ 192.66667],
[ 250. ],...
call方法的正确版本如下:
def __call__(self, x: np.ndarray):
h, w, _ = x.shape
mask = np.zeros((h, w, 1), dtype='float32')
weights = mask.copy()
for i in tqdm(range(0, h - 1, self.stride)):
for j in range(0, w - 1, self.stride):
a, b, c, d = i, min(h, i + self.size), j, min(w, j + self.size)
patch = x[a:b, c:d, :]
mask[a:b, c:d, :] += np.expand_dims(self.predictor(patch), -1)
weights[a:b, c:d, :] += 1
return mask / weights
如果你仍然不知道问题是什么,注意行weights[a:b, c:d, :] += 1。
8.Imagenet归一化
当一个人需要做迁移学习时,用训练Imagenet时的方法将图像归一化通常是一个好主意。
让我们使用熟悉的albumentations来实现:
from albumentations import Normalize
norm = Normalize()
img = cv2.imread('img_small.jpg')
mask = cv2.imread('mask_small.png', cv2.IMREAD_GRAYSCALE)
mask = np.expand_dims(mask, -1) # shape (64, 64) -> shape (64, 64, 1)
normed = norm(image=img, mask=mask)
img, mask = [normed[x] for x in ['image', 'mask']]
def img_to_batch(x):
x = np.transpose(x, (2, 0, 1)).astype('float32')
return torch.from_numpy(np.expand_dims(x, 0))
img, mask = map(img_to_batch, (img, mask))
criterion = F.binary_cross_entropy
现在是时候训练一个网络并对单个图像进行拟合——正如我所提到的,这是一种很好的调试技术:
model_a = UNet(3, 1)
optimizer = torch.optim.Adam(model_a.parameters(), lr=1e-3)
losses = []
for t in tqdm(range(20)):
loss = criterion(model_a(img), mask)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
_ = plt.plot(losses)
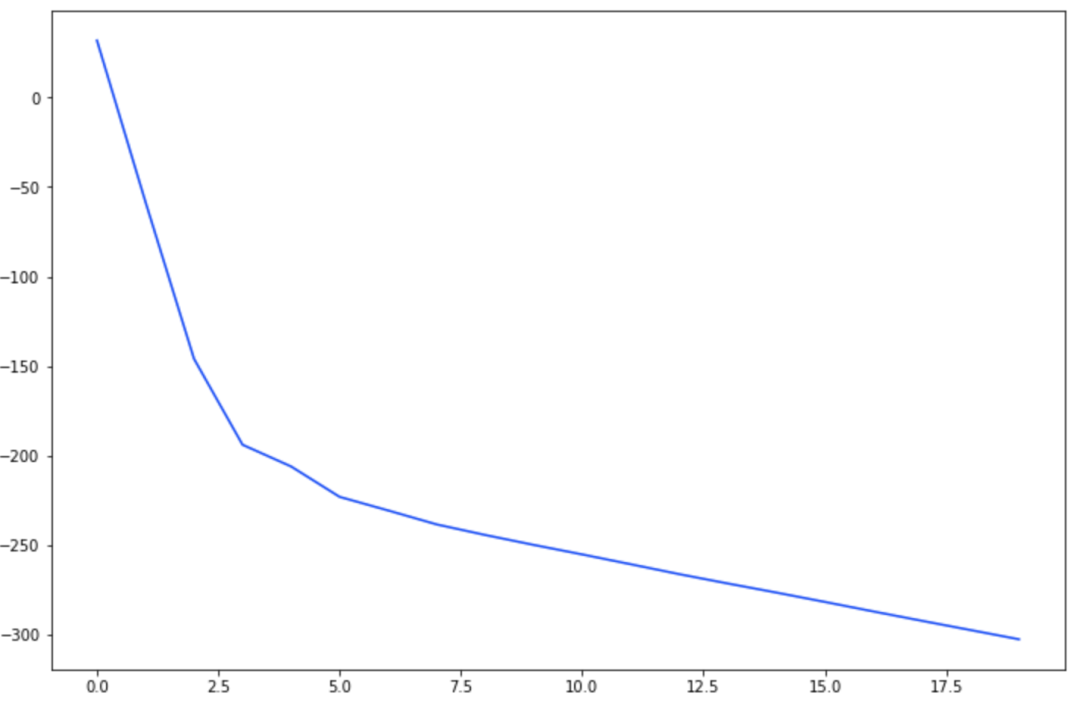
曲率看起来很好,但是-300不是我们期望的交叉熵的损失值。是什么问题?
归一化处理图像效果很好,但掩码需要缩放到[0,1]之间。
model_b = UNet(3, 1)
optimizer = torch.optim.Adam(model_b.parameters(), lr=1e-3)
losses = []
for t in tqdm(range(20)):
loss = criterion(model_b(img), mask / 255.)
losses.append(loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
_ = plt.plot(losses)
在训练循环时一个简单运行断言(例如assert mask.max() <= 1)可以很快地检测到问题。同样,也可以是单元测试。
